Word Embeddings and RNNs
One of the simplest ways to convert words from a natural language into mathematical tensors is to simply represent them as one-hot vectors where the length of these vectors is equal to the size of the vocabulary from where these words are fetched.
For example, if we have a vocabulary of size 8 containing the words:
"a", "apple",
"has", "matrix", "pineapple", "python", "the", "you"
the word "matrix" can be represented as: [0,0,0,1,0,0,0,0]
Obviously, this approach will become a pain when we have a huge vocabulary of words (say millions), and have to train models with these representations as inputs. But apart from this issue, another problem with this approach is that there is no built-in mechanism to convey semantic similarity of words. eg. in the above example, apple and pineapple can be considered to be similar (as both are fruits), but their vector representations don't convey that.
Word Embeddings let us represent words or phrases as vectors of real numbers, where these vectors actually retain the semantic relationships between the original words. Instead of representing words as one-hot vectors, word embeddings map words to a continuous vector space with a much lower dimension.
This mathematical embedding is achieved by a matrix called "embedding matrix". This EM is a matrix of shape (maximum_number_of_words_to_represented,embed_size). ` is the length of the embedded vectors.
In Keras, the embedding matrix is represented as a layer, and maps positive integers (indices corresponding to words) into dense vectors of fixed size (the embedding vectors)
Let's see how word embeddings work.
# colab stuff
# from google.colab import drive
# drive.mount('/content/gdrive')
# DRIVE_BASE_PATH = "/content/gdrive/My\ Drive/Colab\ Notebooks/"
# !pip install -q kaggle
# !mkdir -p ~/.kaggle
# !cp {DRIVE_BASE_PATH}kaggle.json ~/.kaggle/kaggle.json
# !chmod 600 /root/.kaggle/kaggle.json
I'll make use of the data provided in this Kaggle competition where the goal is to classify comments based on how toxic they are.
DATA_PATH = 'data/toxic_comments/'
!kaggle competitions download -c jigsaw-toxic-comment-classification-challenge -p {DATA_PATH}
import numpy as np
import pandas as pd
df_train = pd.read_csv(DATA_PATH+'train.csv.zip', compression='zip')
# df_train.head()
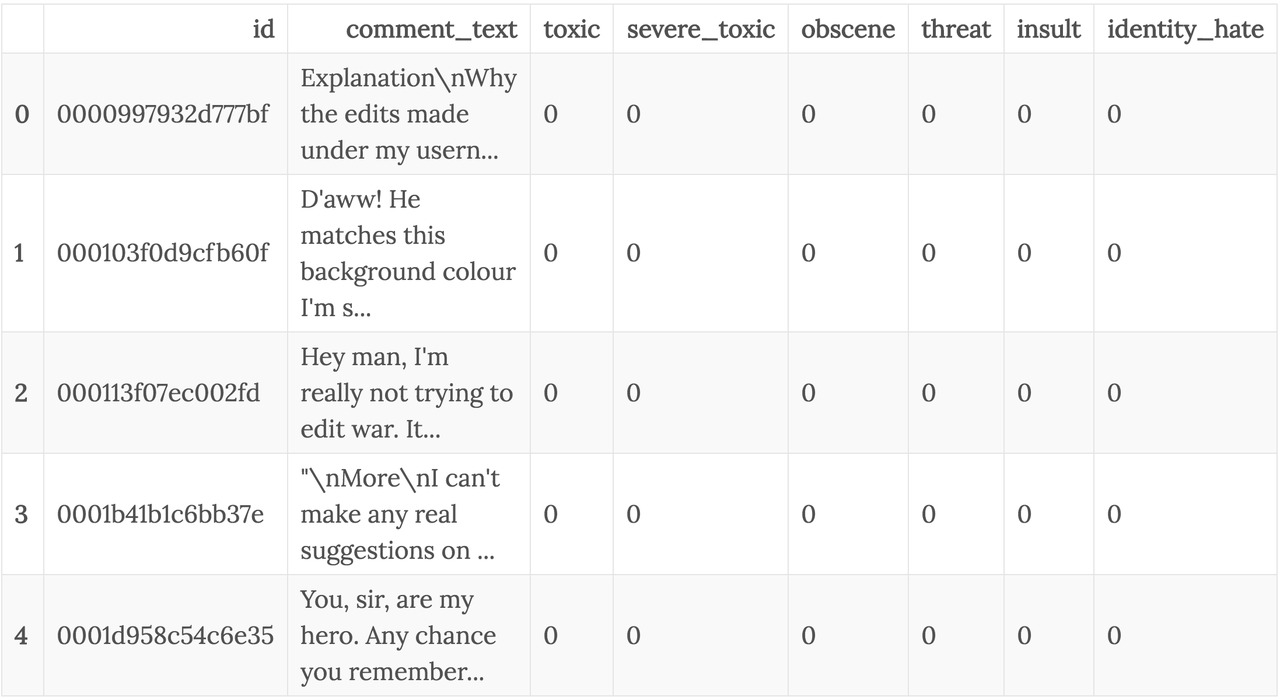
Let's check out some of the comments.
for comment in df_train.head(n=5).comment_text:
print(f'{comment}\n-----\n')
If you go through this data, you'll find that it contains a lot of toxic comments, and the training data is highly unbalanced. Anyways, that's not my focus for now. I just want to make use of this text data to understand (and explain) how word embeddings can help with training models on natural language data.
Next step is to create an embedding matrix. We can start with a randomly initialized matrix and have the model train it, but we don't have the necessary volume of data here to train it. In a lot of cases it makes sense to use pre-trained word vectors. I'll use the glove pre-trained word vectors for this task. Glove offers word vectors trained on different kinds of datasets, like Wikipedia, Twitter, etc. After doing some comparisons I've chosen to use the vectors trained on twitter data. (It sorta makes sense because the comments in the data use informal language similar to tweets)
GLOVE_DIR = 'data/glove/'
!kaggle datasets download -d jdpaletto/glove-global-vectors-for-word-representation -f glove.twitter.27B.50d.txt -p {GLOVE_DIR}
!unzip -q {GLOVE_DIR}glove.twitter.27B.50d.txt.zip -d {GLOVE_DIR}
!ls -R data
WORD_VECTORS_TWITTER_FILE=f'{GLOVE_DIR}glove.twitter.27B.50d.txt'
So the word vector file is made of rows where the first element is the word, and the next embed_size numbers are it's vector representation. I'm using the 50-dimensional-vectors version of glove in this case.
Next step is to generate a dictionary that maps all the words contained in the glove file to their vector representations.
def get_coefs_twitter(word,*arr): return word, np.asarray(arr, dtype='float32')
embeddings_index_twitter = dict(get_coefs_twitter(*o.strip().split()) for o in open(EMBEDDING_FILE_TWITTER))
embeddings_index_twitter['matrix']
One small snag here is that one row has only 50 separate elements. As a result, the word corresponding to that row is a 49 dimensional vector.
s = set(arr.shape for arr in embeddings_index_twitter.values())
print(s)
The next few steps are just to remove that row from the embeddings index dictionary.
for i,el in enumerate(embeddings_index_twitter.values()):
if el.shape[0]==49:
print(i)
!sed '38523q;d' {WORD_VECTORS_TWITTER_FILE}
embeddings_index_twitter['0.45973'].shape
del(embeddings_index_twitter['0.45973'])
set(arr.shape for arr in embeddings_index_twitter.values())
All set. Next step is to tokenize out data. Tokenizing will convert a sentence to an array of word indices, as described below.
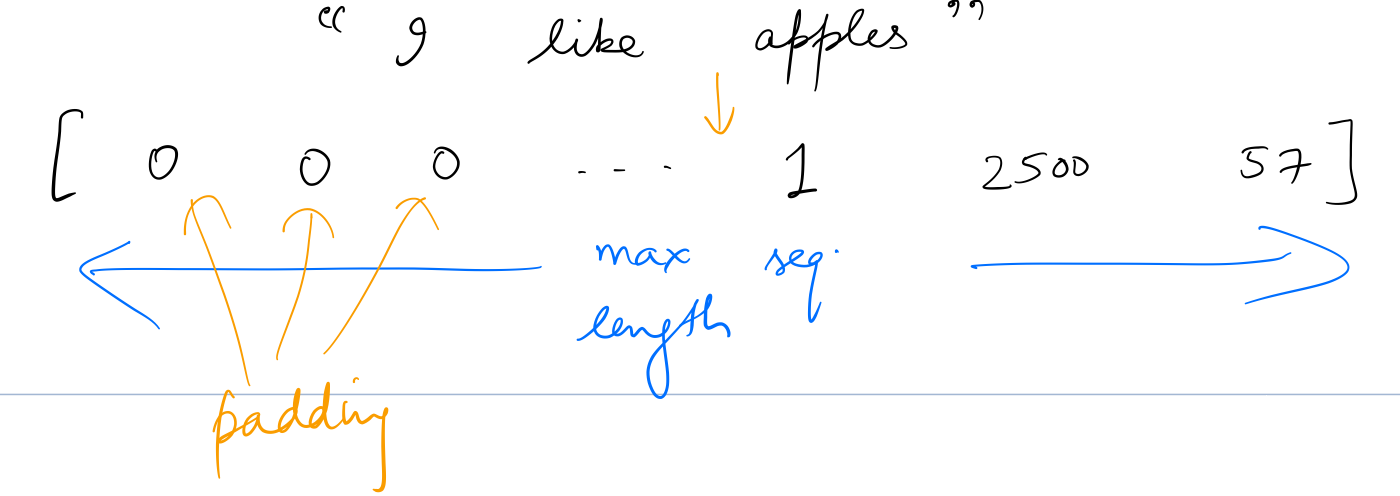
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
I'll work with a subset of the data to make the training a little faster.
df_subset = df_train.sample(frac=1)[:50000]
list_sentences_train = df_subset["comment_text"].fillna("_na_").values
list_classes = ["toxic", "severe_toxic", "obscene", "threat", "insult", "identity_hate"]
y = df_subset[list_classes].values
We need to set the values of a few constants. maxlen defines the max number of words in a sentence. max_features is used by Keras's Tokenizer to select that number of unique words from a set of words input to it.
embed_size = 50 #EMBEDDING_DIMENSION
max_features = 20000
maxlen = 100
tokenizer = Tokenizer(num_words=max_features)
tokenizer.fit_on_texts(list(list_sentences_train))
list_tokenized_train = tokenizer.texts_to_sequences(list_sentences_train)
X_t = pad_sequences(list_tokenized_train, maxlen=maxlen)
print(X_t.shape, y.shape)
Now that the training data is tokenized, we can create an embedding matrix of shape (max_number_of_unique_words_we_tokenized_capped_by_some_upper_limit,embed_size).
We'll use random initialization for words that aren't in GloVe. We'll use the same mean and stdev of embeddings the GloVe has when generating the random values.
all_embs = np.stack(embeddings_index_twitter.values())
emb_mean,emb_std = all_embs.mean(), all_embs.std()
emb_mean,emb_std
word_index = tokenizer.word_index
nb_words = min(max_features, len(word_index))
embedding_matrix = np.random.normal(emb_mean, emb_std, (nb_words, embed_size))
for word, i in word_index.items():
if i >= max_features: continue
embedding_vector = embeddings_index_twitter.get(word)
if embedding_vector is not None: embedding_matrix[i] = embedding_vector
print(embedding_matrix.shape)
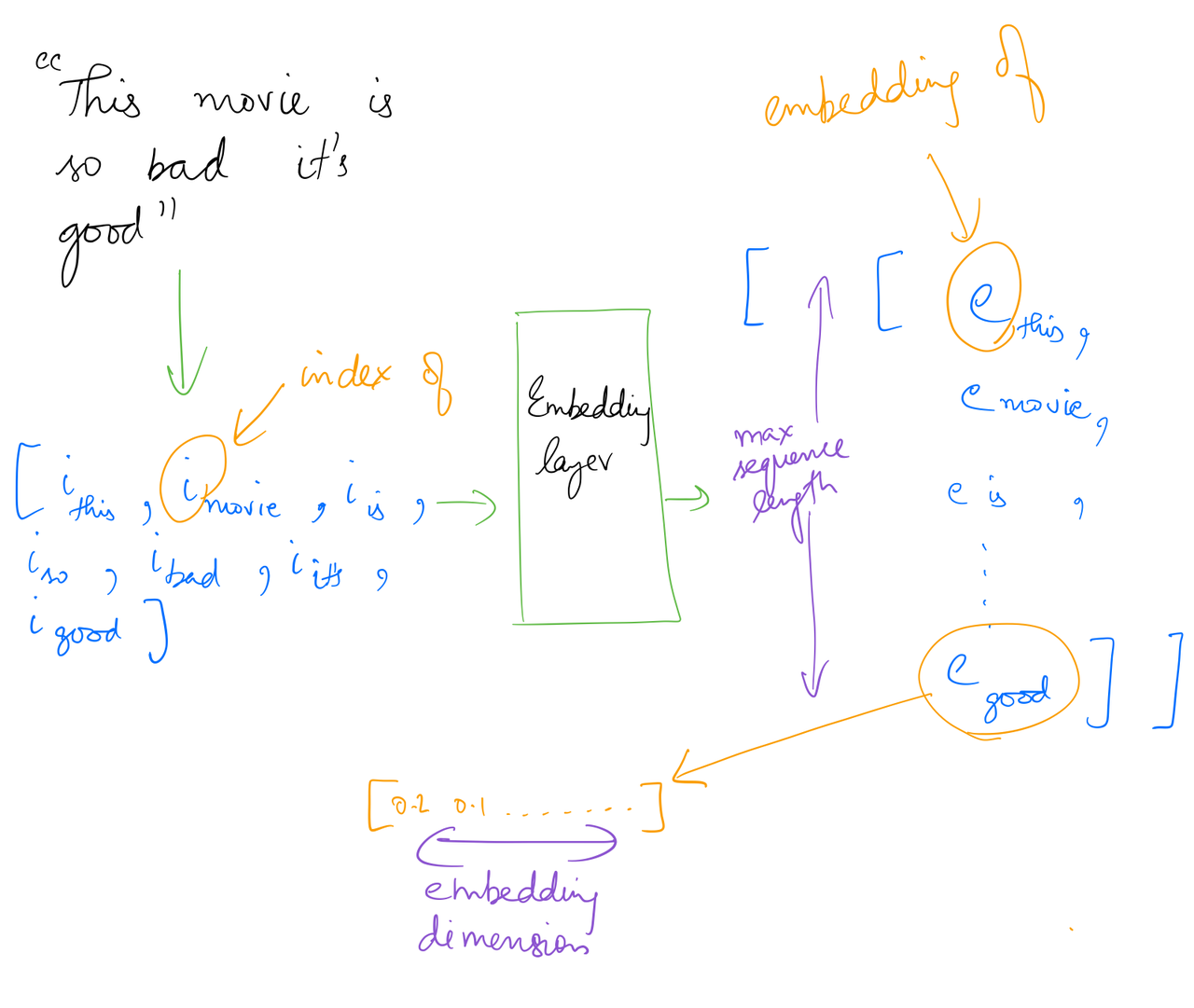
Simply put, each row of this matrix is the vector representation (from glove file) of a word in the word index.
This embedding matrix can then be used as weights for an Embedding layer in a model. We can choose to update these weights during training or not.
So when an input of shape (None, maxlen) is given to this Embedding layer, it will convert it to (None, maxlen, embed_size) as seen in the diagram below.
from keras.layers import Dense, Input, LSTM, Embedding, Dropout, Activation
from keras.layers import Bidirectional, GlobalMaxPool1D
from keras.models import Model
def model():
inp = Input(shape=(maxlen,))
x = Embedding(nb_words, embed_size, weights=[embedding_matrix], trainable=False)(inp)
x = Bidirectional(LSTM(50, return_sequences=True, dropout=0.1, recurrent_dropout=0.1))(x)
x = GlobalMaxPool1D()(x)
x = Dense(50, activation="relu")(x)
x = Dropout(0.1)(x)
x = Dense(6, activation="sigmoid")(x) #sigmoid since this is a multi-label problem
model = Model(inputs=inp, outputs=x)
return model
model = model()
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
model.fit(X_t, y, batch_size=32, epochs=4, validation_split=0.1)
Seems to have started overfitting after the 3rd epoch. A bunch of improvements can be done beyond this baseline, but my main motive behind this exercise was to understand how word embeddings and LSTMs work together.